

@wkorbe My understanding is that nodes fail so infrequently that any performance cost associated with remedying the problems caused by a failed node are acceptable.

It is better to statically allocate map and reduce to nodes, rather than allocate these tasks dynamically. The former reduces network communication costs.

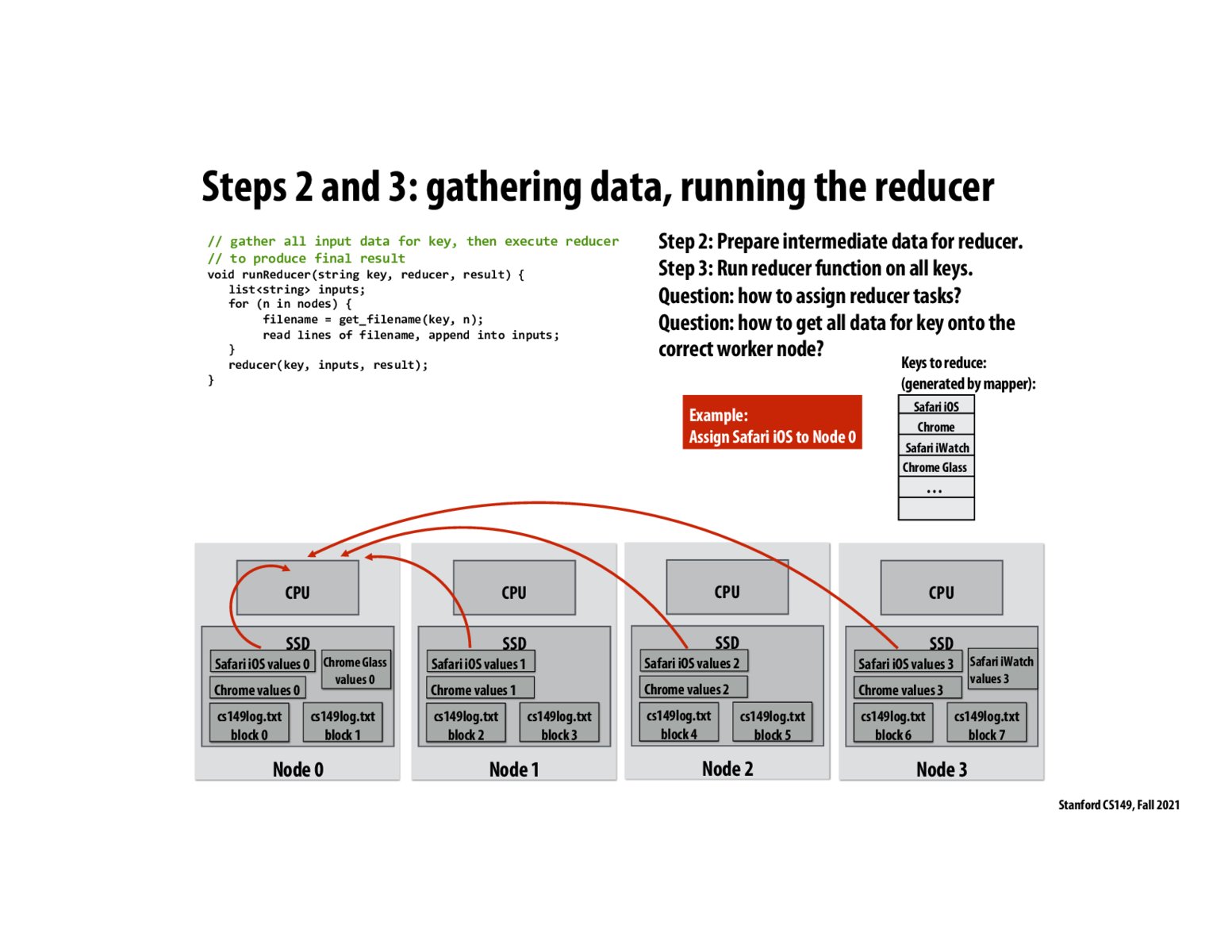
In this example, does that mean the reducer runs on CPU in Node 0 for all hashes, or it just being responsible for reducing with key = Safari iOS? My understanding is the latter case, and all (key, value) with key = Safari iOS will be sent to Node 1 to compute the value, and other key could be sent to other CPU in the nodes, but just want to make sure.

The assignment of a key to a reducer node could be determined by the following mapping. Let the key be k. Then we assign reducer node i to key k where i = hash(k)%numNodes.

To check my understanding, does this design improve on idea 1 from 2 slides earlier because rather than sending an entire block of data to Node 0 to process, the other nodes only have to send the values in their blocks associated with "Safari IOS"?

To follow up on jchao01, the reason idea 1 is bad is not necessarily that it's sequential, but that there is essentially about n*(size of data) amount of computation that is done, because every line from every file has to be sent to all n nodes, and then each of the n nodes can run reduce on ALL keys (or perhaps only one of the keys, by some key assigning mechanism, but even then, communicating every line from every file is already inflating the work done by a lot). In contrast, in idea 2, we each line of each file is sent to only the relevant node. So only (size of data) amount of communication is done. Is this right?

How does the reducer node know when it has received all of the value chunks? For example if one of the mappers is lagging behind for some reason, the reducer needs to wait for that node before it can actually do the reducing computation. Do we just wait for all maps to finish before anyone starts reducing? That would be the easiest way to do this, but it seems like it'd be inefficient from a parallelism perspective.

+1 to fractal1729. This seems like it would also be a difficult place to detect failure without some form of confirmation communication that could take up a lot more recourses on the recipient machines.
Please log in to leave a comment.
If all the values for key "Safari iOS" where sent to Node 0, and Node 0 went down, it seems we would need to rerun what Node 0 did on another node, say Node 4, but we also would need to have Nodes 1-3 resend their data to the new Node (Node 4), unless Node 4 was already designated as a backup for Node 0 whom received the same data as Node 0 from Nodes 1-3 concurrently. I'm wondering what the resiliency design actually is here and if we have knobs to turn to reach the level of safety to performance to cost we are comfortable with?