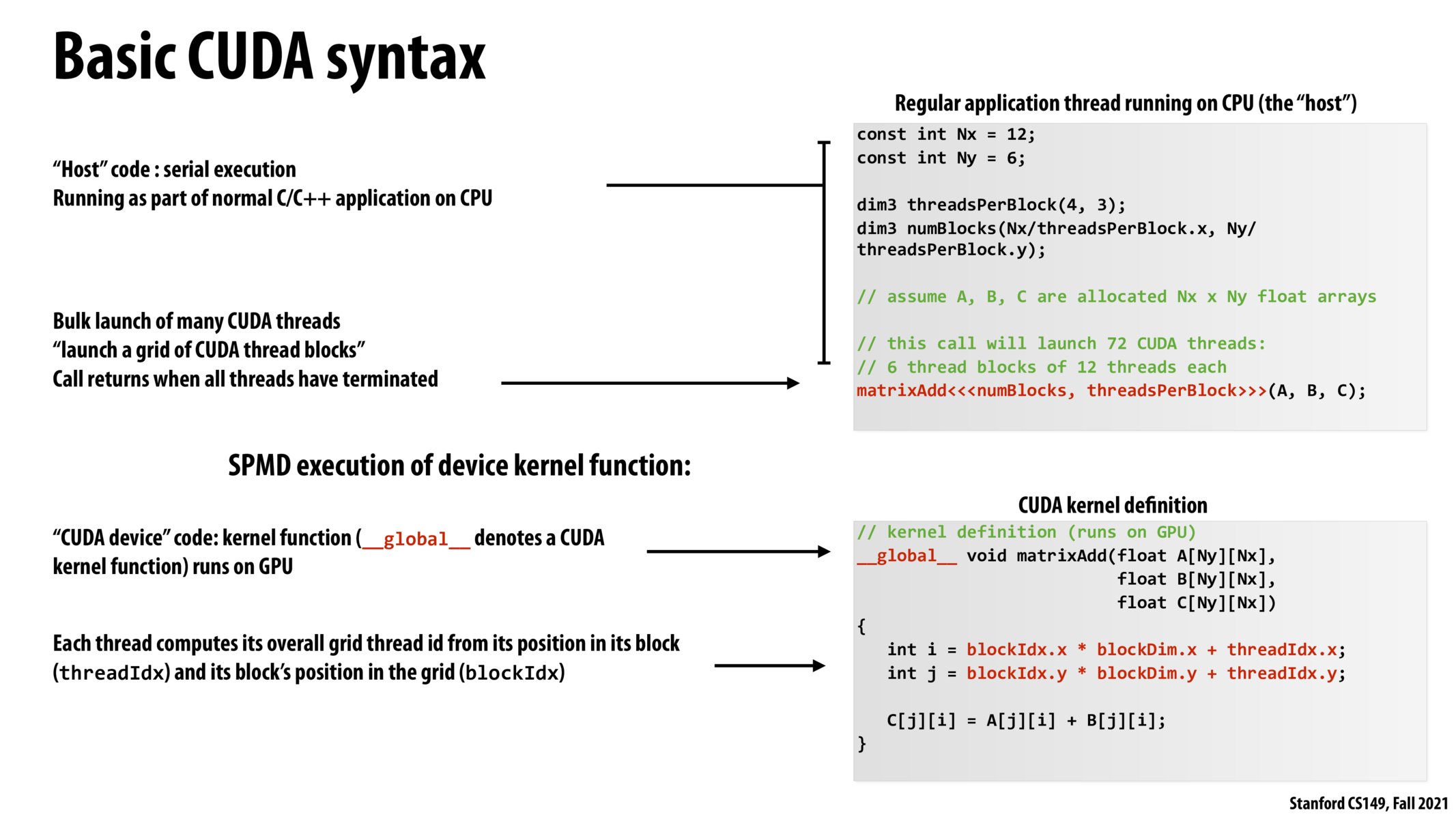


@evs, I believe the takeaway from lecture was that GPU designers like Nvidia deny an underlying SIMD implementation, but the GPU hardware is constantly looking to see if different threads are performing the same operation and will parallelize such operations in a manner reminiscent of SIMD. So I think the answer is mostly yes - CUDA/GPUs take advantage of parallel work whenever the opportunity presents itself.

Some math recap: in this program, there are Nx * Ny = 126=72 elements that can be processed all in parallel. Each CUDA thread block has 43=12 cuda threads, and thus we need 72/12 = 6 CUDA thread blocks to compute for all elements. Each CUDA thread works on 1 of the 72 input element, so there are 72 cuda threads in total (12 cuda threads per block).

It's quite cool to see that the SPMD abstraction semantics we learned earlier in the course (back in ISPC days) are also a central part of programming in CUDA!
Please log in to leave a comment.
Since theres a lot of repeated steps here. Will CUDA be implementing these threads with SIMD?